
Utforsk lysterapi med LED-maske for lysbehandling i ansiktet
Lysterapi har alltid vært et fascinerende tema, og i de senere årene har bruken av LED-masker virkelig tatt av. LED-lysterapi har revolusjonert hudpleiebransjen, og det er mange gode grunner til at dette er tilfellet. Hva er LED-lysterapi? En introduksjon til lysterapi Lysterapi, eller fototerapi, er en teknikk der huden utsettes …

Søkemotoroptimalisering: Din nøkkel til digital suksess
Søkemotoroptimalisering, bedre kjent som SEO, er en fantastisk måte å få nettstedet ditt til å skinne i Googles søkemotorresultater. Ønsker du at bedriften din skal dominere rangeringen og få mer trafikk? Da trenger du en profesjonell SEO-tjeneste som tilbyr eksepsjonelle lenker og kvalitetsinnhold. Mementor er det ultimate valget for å …
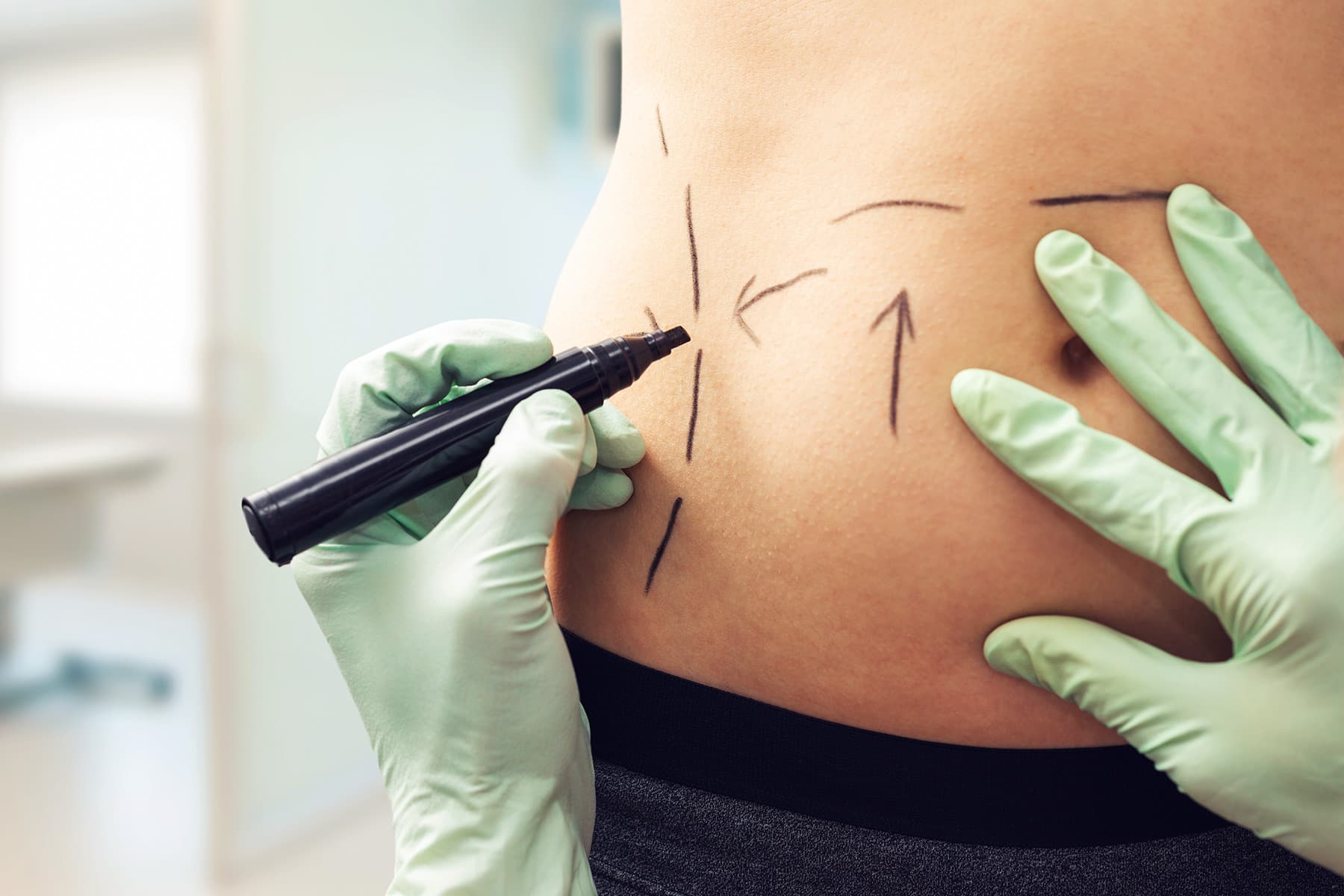
Fettsuging og fjerning av uønsket fett
Fettsuging er et kosmetisk inngrep som fjerner fett som man ikke blir kvitt gjennom kosthold og trening. Det er ikke alt fett som lar seg fjerne naturlig og da kan fettsuging være løsningen for deg. Inngrepet blir vanligvis utført på hofte, mage, lår, rumpe, rygg, armer og under haken eller …

Covid-19 selvtest
Mange ønsker å forsikre seg om at de ikke er smittet av covid-19 før de deltar i sosiale sammenkomster. Det er også mange som ønsker å sjekke hvorvidt de har blitt smittet etter å ha deltatt på arrangementer eller lignende. Med en covid-19 selvtest kan du raskt og enkelt teste …

Speil fra da til nå
Speil er i dag like populært som utsmykking og dekorativ detalj, som det var tilbake i middelalderen og enda lengre tilbake i oldtiden. For å si det mildt så har ikke speilet mistet sin glans. Det er både et møbel i tillegg til å være et arkitektonisk poeng og detalj.…

Nettapotek har mange muligheter
Vi har for lengst beveget oss inn i en digital verden og ville hatt vanskeligheter med å forestille oss et liv uten internett og nettjenester. Se bare nå på hvordan vi i store deler av verden har med vitende og vilje fysisk isolert oss i en periode, men opprettholder livene …
Oolong te kan bedre din helse
Oolong te er en blanding av te som er veldig mørk i fargen, noe som er en egenskap den oppnår fra produksjonsprosessen der tebladene er tørket grundig under solen til fargen deres blir veldig mørk. Det er der den får navnet fra, fordi den direkte oversettelse for Oolong te er …

VPN bruksområder
VPN er en forkortelse for det engelske begrepet Virtual Private Network. På norsk betyr dette ganske praktisk sett Virtuelt Privat Nettverk, slik at også vi kan bruke forkortelsen VPN. Teknologien har bare over de siste par årene vokst helt massivt i popularitet, og i dag brukes denne teknologien av mange …

Velg et moderne webdesign for ditt nye nettsted
Når man skal sette opp et nytt nettsted, så er det viktig å tenke gjennom hvordan man ønsker å presentere sitt budskap til lesere eller til kunder. I dag finner man de fleste virksomheter på internett, og på grunn av det vil det også være stor konkurranse om kundene. Det …

Kan man få tak i alle bildeler på nett?
Amatørmekanikere som profesjonelle kjøper i dag ofte bildeler på nett. Dette er en praktisk måte for å få bestilt bildelene man ønsker, og det er noe man kan sette seg ned å gjøre med en gang man ser at behovet oppstår. Men mange er ennå ikke helt sikre på om …









Siste innlegg
- Utforsk lysterapi med LED-maske for lysbehandling i ansiktet

- Søkemotoroptimalisering: Din nøkkel til digital suksess
- Fettsuging og fjerning av uønsket fett
- Covid-19 selvtest



Tagger
Alkohol Alkoholforbruk Alkoholisme apotek på nett bildeler bildeler på nett BMI covid-19 covid-19 selvtest Digital markedsføring fettsuging forbrukslån hvite tenner kirurgiske inngrep Kosmetisk kirurgi LED-maske lysbehandling lysterapi lån nettapotek nettbutikk Oolong te Renhold renholdsfirma rusavhengighet selvtest SEO speil Søkemotoroptimalisering tannbleking te uønsket fett vpn tjeneste webdesign Webteknologi